Bem-vindo ao BookScraper, um projeto de Python que combina web scraping e visualização de dados para explorar informações de livros disponíveis no site Books to Scrape.
Com este projeto, você poderá:
- Extrair dados como títulos e preços de livros.
- Armazenar essas informações em um arquivo CSV.
- Visualizar insights através de uma dashboard interativa criada com Streamlit.
Este projeto foi desenvolvido com o objetivo de demonstrar habilidades em:
- Web Scraping: Coleta de informações automatizada de páginas web.
- Análise de Dados: Organização e processamento dos dados extraídos.
- Visualização de Dados: Criação de dashboards interativas e acessíveis.
Além disso, é uma oportunidade para aprender e explorar bibliotecas poderosas como:
BeautifulSoup: Para scraping de dados.Pandas: Para manipulação e análise de dados.Streamlit: Para criação de dashboards.
git clone https://github.com/marioleo7k/bookscraper
cd bookscraperCertifique-se de que você tem o Python instalado e execute o comando:
pip install -r requirements.txtExecute o script bookscraper.py para realizar o web scraping e gerar o arquivo livros.csv:
python bookscraper.pyExecute a dashboard interativa:
streamlit run bookscraper_dashboard.pyAcesse a URL local exibida no terminal, como http://localhost:8501.
- O script
bookscraper.pycoleta automaticamente:- Títulos dos livros.
- Preços em Libras Esterlinas (£).
- Gera um arquivo CSV com os dados extraídos.
- A dashboard, criada com Streamlit, inclui:
- Distribuição de Preços: Visualize a variação de preços em um histograma.
- Top 10 Livros Mais Caros: Descubra os livros mais caros.
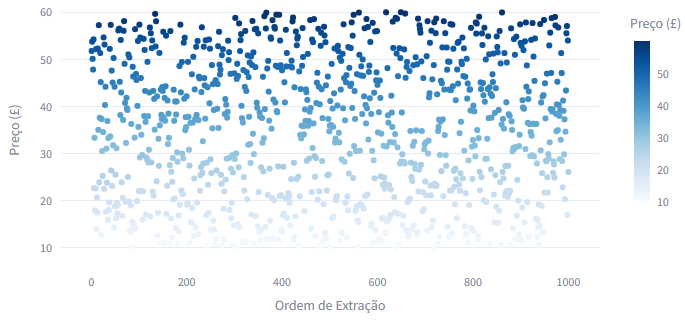
- Preço por Ordem de Extração: Um gráfico de dispersão para acompanhar os preços na sequência.

A estrutura de arquivos do repositório está organizada da seguinte forma:
bookscraper/
├── bookscraper.py # Script de extração de dados
├── bookscraper_dashboard.py # Script da dashboard
├── livros.csv # Dados extraídos (gerado pelo scraper)
├── requirements.txt # Dependências do projeto
├── .gitignore # Arquivos ignorados pelo Git
└── README.md # Documentação do projeto
Este projeto está sob a licença MIT. Consulte o arquivo LICENSE para mais detalhes.
Para dúvidas ou feedback:
- LinkedIn: Mario Leonardo da Silva
- E-mail: [email protected]
Você também pode acessar a versão publicada da dashboard aqui.