proposal: encoding/json/v2: new API for encoding/json #71497
Comments
Changes from discussionIf you have already read the discussion in #63397, then much of the API presented above may be familiar. This section records the differences made relative to the discussion. Package "encoding/json/jsontext"The following - func (v Value) IsValid() bool
+ func (v Value) IsValid(opts ...Options) bool
- func (v *Value) Compact() error
+ func (v *Value) Compact(opts ...Options) error
- func (v *Value) Indent(prefix, indent string) error
+ func (v *Value) Indent(opts ...Options) error
- func (v *Value) Canonicalize() error
+ func (v *Value) Canonicalize(opts ...Options) error
+ func (v *Value) Format(opts ...Options) errorAccepting options allows the default behavior of these methods to be overridden, providing greater flexibility in usage. The removal of the One major criticism of The The following options were added to provide greater flexibility to formatting: + func CanonicalizeRawFloats(v bool) Options
+ func CanonicalizeRawInts(v bool) Options
+ func PreserveRawStrings(v bool) Options
+ func ReorderRawObjects(v bool) Options
+ func SpaceAfterComma(v bool) Options
+ func SpaceAfterColon(v bool) Options
- func Expand(v bool) Options
+ func Multiline(v bool) OptionsThe The following formatting API has been added: + func AppendFormat(dst, src []byte, opts ...Options) ([]byte, error)
+ func AppendQuote[Bytes ~[]byte | ~string](dst []byte, src Bytes) ([]byte, error)
+ func AppendUnquote[Bytes ~[]byte | ~string](dst []byte, src Bytes) ([]byte, error)The length returned by -func (e *Encoder) StackIndex(i int) (Kind, int)
+func (e *Encoder) StackIndex(i int) (Kind, int64)
-func (d *Decoder) StackIndex(i int) (Kind, int)
+func (d *Decoder) StackIndex(i int) (Kind, int64)The pointer returned by - func (e *Encoder) StackPointer() string
+ func (e *Encoder) StackPointer() Pointer
- func (d *Decoder) StackPointer() string
+ func (d *Decoder) StackPointer() PointerAn explicit + type Pointer string
+ func (p Pointer) IsValid() bool
+ func (p Pointer) AppendToken(tok string) Pointer
+ func (p Pointer) Parent() Pointer
+ func (p Pointer) Contains(pc Pointer) bool
+ func (p Pointer) LastToken() string
+ func (p Pointer) Tokens() iter.Seq[string]Handling of errors was improved: type SyntacticError struct {
...
- JSONPointer string
+ JSONPointer Pointer
}
+ var ErrDuplicateName = errors.New("duplicate object member name")
+ var ErrNonStringName = errors.New("object member name must be a string")The Package "encoding/json/v2"Interface types and methods were renamed to avoid the - type MarshalerV1 interface { MarshalJSON() ([]byte, error) }
+ type Marshaler interface { MarshalJSON() ([]byte, error)}
- type MarshalerV2 interface { MarshalJSONV2(*jsontext.Encoder, Options) error }
+ type MarshalerTo interface { MarshalJSONTo(*jsontext.Encoder, Options) error}
- type UnmarshalerV1 interface { UnmarshalJSON([]byte) error }
+ type Unmarshaler interface { UnmarshalJSON([]byte) error}
- type UnmarshalerV2 interface { UnmarshalJSONV2(*jsontext.Decoder, Options) error }
+ type UnmarshalerFrom interface { UnmarshalJSONFrom(*jsontext.Decoder, Options) error}
- func MarshalFuncV1[T any](fn func(T) ([]byte, error)) *Marshalers
+ func MarshalFunc[T any](fn func(T) ([]byte, error)) *Marshalers
- func MarshalFuncV2[T any](fn func(*jsontext.Encoder, T, Options) error) *Marshalers
+ func MarshalToFunc[T any](fn func(*jsontext.Encoder, T, Options) error) *Marshalers
- func UnmarshalFuncV1[T any](fn func([]byte, T) error) *Unmarshalers
+ func UnmarshalFunc[T any](fn func([]byte, T) error) *Unmarshalers
- func UnmarshalFuncV2[T any](fn func(*jsontext.Decoder, T, Options) error) *Unmarshalers
+ func UnmarshalFromFunc[T any](fn func(*jsontext.Decoder, T, Options) error) *UnmarshalersThe constructor for - func NewMarshalers(ms ...*Marshalers) *Marshalers
+ func JoinMarshalers(ms ...*Marshalers) *Marshalers
- func NewUnmarshalers(us ...*Unmarshalers) *Unmarshalers
+ func JoinUnmarshalers(us ...*Unmarshalers) *UnmarshalersThe following options were added: + func OmitZeroStructFields(v bool) Options
+ func NonFatalSemanticErrors(v bool) OptionsThe Implementing v1 in terms of v2 required the latter to support non-fatal errors. The type SemanticError struct {
...
- JSONPointer string
+ JSONPointer jsontext.Pointer
+ JSONValue jsontext.Value
}
+ var ErrUnknownName = errors.New("unknown object member name")The The following behavior changes were made to marshal and unmarshal:
Package "encoding/json"Some options for legacy v1 support were renamed or had similar options folded together. - func RejectFloatOverflow(v bool) Options
- func IgnoreStructErrors(v bool) Options
- func ReportLegacyErrorValues(v bool) Options
+ func ReportErrorsWithLegacySemantics(bool)
- func SkipUnaddressableMethods(v bool) Options
+ func CallMethodsWithLegacySemantics(bool)
- func FormatByteArrayAsArray(v bool) Options
+ func FormatBytesWithLegacySemantics(bool)
- func FormatTimeDurationAsNanosecond(v bool) Options
+ func FormatTimeWithLegacySemantics(bool)
+ func EscapeInvalidUTF8(bool)In general, many options were renamed with a The The The + func (Number) MarshalJSONTo(*jsontext.Encoder, jsonopts.Options) error
+ func (*Number) UnmarshalJSONFrom(*jsontext.Decoder, jsonopts.Options) errorThe type UnmarshalTypeError struct {
...
+ Err error
}
+ func (*UnmarshalTypeError) Unwrap() errorChanges not made from discussionThere were many ideas discussed in #63397 that did not result in changes to the current proposal. Some ideas are still worth pursuing, while others were declined for various reasons. In general, ideas that could later be built on top of the initial release of v2 were deferred so that we could focus on the current API. We prioritized ideas that could not be explored after the initial API was finalized. The following is a non-exhaustive list of such considerations:
Changes since proposalSince the filing of this proposal, some changes were made in response to feedback:
|
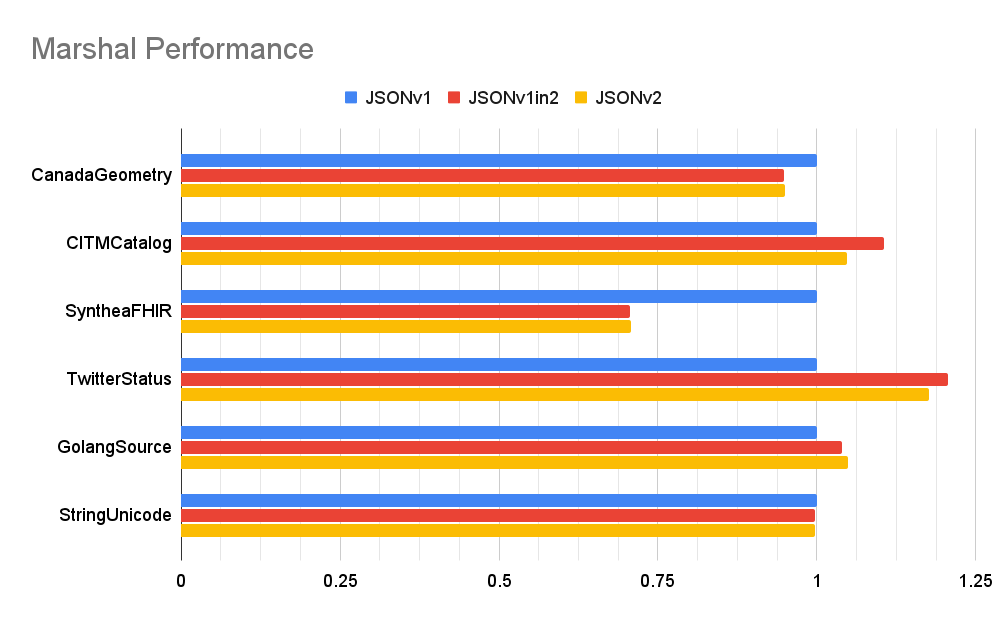
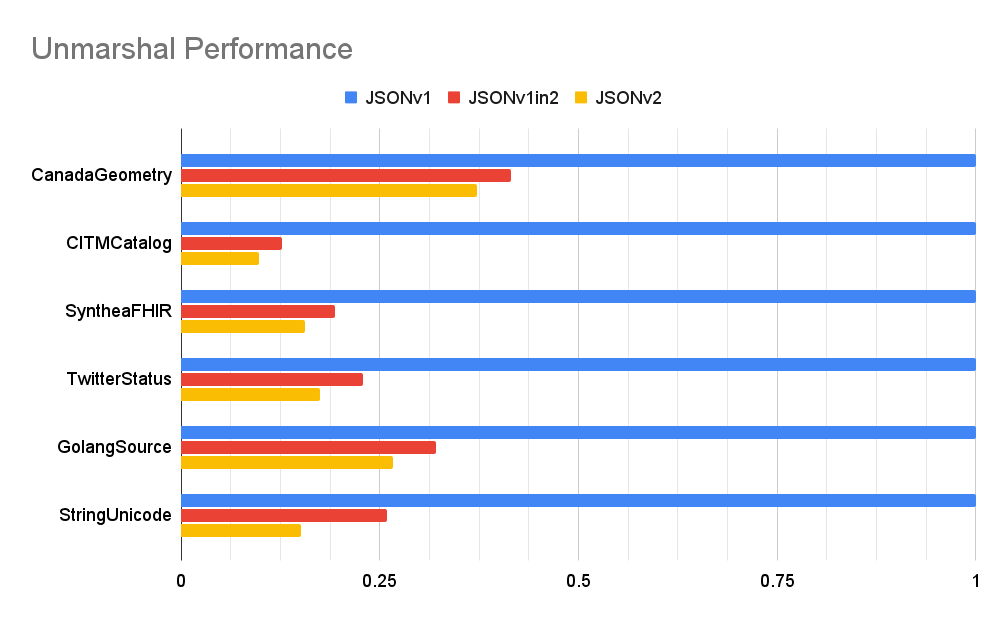
Proposed implementationThis proposal has been implemented by the If this proposal is accepted, the implementation in We may also provide a PerformanceFor more information, see the The following benchmarks compares performance across several different JSON implementations:
The Benchmarks were run across various datasets:
All of the charts are unit-less since the values are normalized relative to
When marshaling, Compared to high-performance third-party alternatives, the proposed "encoding/json/v2" implementation performs within the same order of magnitude, indicating near-optimal efficiency.
When unmarshaling, Compared to high-performance third-party alternatives, the proposed "encoding/json/v2" implementation performs within the same order of magnitude, indicating near-optimal efficiency. While maintaining a JSON state machine hurts the v2 implementation in terms of performance, it provides the ability to marshal or unmarshal in a purely streaming manner. This feature is necessary to convert certain pathological O(N²) runtime scenarios into O(N). For example, switching from |
|
Thanks! This really looks great. Does It seems to me there is no way to provide custom (i.e., non-standard) options? |
The current behavior is that func (v T) MarshalJSONTo(enc *jsontext.Encoder, opts json.Options) error {
type TNoMethods T
return json.MarshalEncode(enc, TNoMethods(v), opts)
}
We're going to withhold this for the initial release of v2, but propose something as a follow-up. I still believe it's an important feature, but we're making a conscious decision to limit the scope of v2, which is already large. If you're interested, there's a prototype API for user-defined options in go-json-experiment/json#138. One of my comments also scopes out a possible API for specifying format flags for particular types. |
|
Thank you for this great work. Will |
|
@dsnet Thanks for the response. Seems reasonable.
Yes, and this is why I worry that in the future we will never be able to add this in backwards compatible way, unless this is added from the beginning. The rest can be extended easier. My design goal is really that (Oh, are all struct tags for a given field even available through
I must say I do not get how your example can simulate behavior of, for example, |
I don't feel like this comparison is fair since:
I don't think it's difficult to learn/understand, but I'd prefer constants. I tend to prefer them so gopls recommends correct values and to avoid accidental misspellings that the compiler can catch. |
This comment has been minimized.
This comment has been minimized.
|
The design seems sound, although I'd have hoped for fewer options. On the performance front, what do the benchmarks show about memory consumption and gc behavior? I found v1 to use unreasonable amounts of memory, and this included the streaming interface. |
|
Yay , you implemented v1 in terms of v2 !!! In case you think that's minor, updaters and downdaters are much-reinvented improvements, used in Multics, Solaris and GNU libc. All too many other folks don't and suffer from "flag days" when everything has to change at once (:-)) For more detail on why this is cool, see Paul Stachour's "Jack" article , https://cacm.acm.org/practice/you-dont-know-jack-about-software-maintenance/ |
|
While I agree with the reasoning of the
Given the options I would rather have a more specific name that may include other behaviors than a bunch of similarly named ambiguous options that really require historical context to fully understand. However given these are mostly used for transitional and discourages for general use maybe that is ok? |
This comment has been minimized.
This comment has been minimized.
@timbray: The v2 implementation allocates less than most alternatives: This is most likely due to v2's use of a string intern cache. Aside from strings, unfortunately most other data structures fundamentally have to be allocated. The memory regions discussion #70257 could provide a way to batch allocations together in a single region, which is freed all together. |

{kind=link}
{kind=link}
|
@nemith, the number of legacy options makes me sad as well. When we first started to implement v1 in terms of v2, we thought we could have just a few targeted options with clear names, but it became increasingly clear that there were too many odd behaviors of v1 to have individual options for. Many of these behaviors are arguably bugs, but have practically become stable behavior in v1 as a result of Hyrum's Law. Of all the options to achieve 100% known compatibility, they roughly fell into three categories:
Options in category 3 could use further refinement. For example, it might make sense to split:
|
@a-pav In the end we decided to focus on what's blocking v2 from getting the stdlib, so we made a conscious decision not to include that for the initial release. Supporting I'll update the "Changed from discussion" to include a sub-section on changes that we did not end making. |
|
It seems odd for Encoder method names to use "Write" instead of "Encode", and for Decoder method names to use "Read" instead of "Decode": func (*Encoder) WriteToken(Token) error
func (*Encoder) WriteValue(Value) error
func (*Decoder) ReadToken() (Token, error)
func (*Decoder) ReadValue() (Value, error)because encoding/json uses "Encode" and "Decode": func (enc *Encoder) Encode(v any) error
func (dec *Decoder) Decode(v any) errorand encoding/xml does too: func (enc *Encoder) Encode(v any) error
func (enc *Encoder) EncodeToken(t Token) error
func (d *Decoder) Decode(v any) error
WriterTo and ReaderFrom push to, or pull from, entire byte streams. That seems useful for JSON marshaling too. Users have already written MarshalJSON/UnmarshalJSON methods, and enabling users to add a byte stream version of those methods alongside would be an nice way to opt into better performance with little effort. The MarshalJSON/UnmarshalJSON implementations could just be calls to the stream version with a bytes.Buffer. Perhaps something like: MarshalJSONToWriter(io.Writer, Options) error
UnmarshalJSONFromReader(io.Reader, Options) errorThen we'd have: MarshalJSONToEncoder(*jsontext.Encoder, Options) error
UnmarshalJSONFromDecoder(*jsontext.Decoder, Options) error
I would guess that had more to do with enabling custom or future standard HTTP methods. Having to remember There appears to be a misspelling in the name |
Why do these take an Options? Is it just in case they invoke the JSON library themselves? If so, what is an example of when that would be useful? And if so, why not have
Does this mean the whitespace formatting options are all true by default? Which options are related to whitespace formatting? I see comments like Is it possible to have all default values be zero values? If so, then we wouldn't need this declaration.
Apparently Options is a map? Or is that just for illustrative purposes? What is the underlying type of Options?
There are a lot of functions that take variadic Options. Why not a single Options, since multiple Options can be combined with JoinOptions, like for MarshalJSONTo, UnmarshalJSONFrom, MarshalToFunc, and UnmarshalFromFunc? Conversely, why not just deal with []Option everywhere, like functional options? |
|
This declaration in jsonv1 doesn't seem to be used.
Missing square brackets around declaration names. "Options configure" seems like a number disagreement between subject and verb. Options is a singular type, so it should be "Options configures".
It seems odd for Options to not be the second param in fn, like in MarshalJSONTo and UnmarshalJSONFrom. |
I don't see a DefaultOptionsV1 in jsonv2, so I don't see a need for the V2 suffix in jsonv2. Users could use qualified imports to distinguish between the two declarations in jsonv1 and jsonv2.
Exporting this perpetuates bad JSON and bad behavior with jsonv2, and complicates the public options API. In my opinion, there shouldn't be a way to enable this behavior in jsonv2 unless it's coming from jsonv1 under the hood. Options like jsontext.AllowInvalidUTF8 should be moved to an internal package shared by jsonv1, jsonv2, and jsontext to hide them. That way, jsonv1 gets the improved performance of jsonv2, the jsonv1 and jsonv2 public API isn't cluttered by compatibility concerns, and jsonv1 users are motivated to upgrade to jsonv2 for better behavior and features. |
How would this affect encoding? |
|
Why aren't Perhaps GitHub IntelliSense is failing me, but I don't see that the Value methods that take Options are used in the implementation, so I assume they're meant for users only. jsonv1.RawMessage is changed to alias jsontext.Value, so they seem to be analogous. I've never used RawMessage myself, but its documentation says it's for delaying a JSON decoding, or precomputing a JSON encoding, in the context of being a Marshaler/Unmarshaler value. I don't see how the above-mentioned Value methods relate to those use cases; they seem to only be for encoding. When would we want to use them instead of using the Value with an Encoder or Decoder? |
|
The names in
The only exceptions to this pattern I could find are HTTP-related, which were probably authored at around the same time:
Yet even those names are the minority of HTTP sub-package names. No "http" prefixes here:
I don't see why
|
|
It seems like |
|
The package name "jsontext" doesn't seem right to me. JSON is text. It would be like naming a package "jpegbinary". Perhaps "syntax" or "jsonsyntax" would be better than "text" or "jsontext".
Why are we splitting the encoding and marshaling code into separate packages, again? What I mean is, where is the concrete evidence that justifies the split in terms of who asked for it, the scenarios they need it for, the min/avg/max space savings in those scenarios, how important those savings are in those scenarios, etc. @dsnet said in the GitHub discussion for this that his employer Tailscale needs it to avoid the slightly larger binary size that using reflection causes, but one employer saving a few megabytes of memory is alone hardly justification for the cost of splitting the encoding and marshaling code. Having all the code together is easy to use and fits the stdlib pattern, so it seems to me there needs to be a very compelling reason for the interests of the majority of the Go Community to be served by doing this split. As shown above, this design isn't all upside, it's striking a trade-off, and for us to judge whether it's the right trade-off, we need that concrete evidence. (Apologies if I missed it.) Where is the line drawn for using reflection? Is |
|
Love it. I’ve painted myself into naming corners using the word Legacy. I’d suggest s/Legacy/V1/g. Shorter and more precise. |
|
Hi @willfaught, I appreciate your great enthusiasm in providing feedback. I believe it be more productive to condense your thoughts down to the most significant ideas so that we don’t overwhelm the discussion. 20+ thoughts spread throughout 9 distinct posts is challenging for others to follow and engage with even they are worth discussing. We appreciate your thoughts, but not all thoughts are equally fruitful to discuss. This particular proposal is paired with a working prototype, so some of the questions could be answered on your own by running some code in a playground. Suggestions about spelling errors or nuances of documentation are better filed at github.com/go-json-experiment/json. Some of the points you raised have already been addressed in the prior discussion (#63397). While ideas may have merit, engineering is about tradeoffs and so we sometimes still choose to go down a different path even when presented with valid counter-arguments. For the sake of this proposal, we should focus on API that cannot be changed once this has been proposed and merged. I recommend choosing a small set of issues that you believe are the most significant and bring the most value. You’re welcome to re-raise a concern already discussed, but let’s aim to keep it a singular issue or two that you believe is most important. In general, it’s most effective to keep a single comment to a single cohesive thought. GitHub supports emojis, which allows others to signal whether they agree (or disagree) with the idea. Multiple thoughts per comment confuses this reaction mechanism. For example, @prattmic’s comment on naming of |
|
From the example for Number I see this if dec.PeekKind() == '0' {
*val = jsontext.Value(nil)
}Which makes me even more think that constants are the way to go. Reading this as "peeking at the kind to see if it is zero" and then taking a couple of seconds to realize that 0 mean number is just too confusing for me. This is made worse that I still find the analogy to HTTP methods to be flawed as the use in spec and intentional expansion (new methods are allowed in HTTP are new tokens going to ever be in JSON?) to not be the same. If the worry is abuse in use then just make the Kind completely opaque? (Edit: It is also unclear why Kind needs to be byte character at all. I am not against it and it feels clever but the HTTP argument goes away when they are represented by anything else) I am also already missing |
|
I just filed #71756 for adding |
|
#71756 raises the prospect of another package. Can enough declarations move such that the MarshalerTo / UnmarshalerFrom interface methods take an interface instead of a concrete Encoder / Decoder? |
|
I'm not sure I see the connection with splitting "jsontext" apart and whether In the future, we could technically still support third-party encoder implementations by allowing users to register a custom implementation into the Thus far, I haven't been convinced of the need for third-party implementations to justify that the flexibility wins outweights the performance hit of interfaces. |
|
I was thinking less about third party implementations, and more about making the interfaces implementable without pulling in so many dependencies. |
|
I see, so in relation to the earlier discussion that "time" should directly implement |
|
I'm trying to implement UnmarshalerFrom for my struct. It seems that I cannot reach comparable performance without access to the I propose adding this Method to jsontext.Decoder: // DisableDuplicateNameCheck disables the duplicate name check for the current decoding object for better performance.
// Call this just after reading '{' token.
// Returns whether the caller should run its own check, depending on whether [AllowDuplicateNames] is set.
DisableDuplicateNameCheck() bool |
This comment has been minimized.
This comment has been minimized.
@dsnet It seems to me that the types of the fields in SemanticError make it clear which type system they pertain to: Pointer jsontext.Pointer
Kind jsontext.Kind
Value jsontext.Value
Type reflect.TypeBy the way, the type of JSONKind in the proposal is |
@dsnet It strikes me as improper for you to moderate, shape, or discourage the discussion of your own proposal because you have a conflict of interest. For the proposal process to be perceived as fair, productive, and useful, it should avoid the appearance of impropriety. Frankly, I was so dismayed by your behavior that I walked away from this discussion a couple weeks ago, and I regret participating in it. I don't plan to stay involved past wrapping up this comment.
The prior GitHub Discussion wasn't part of the proposal process. That was for you to gather early feedback. This GitHub Issue is for us, the Go Community, to vet the final proposal, and part of that vetting is pointing out issues that were raised before that haven't been properly addressed in some peoples' estimation. Many people here may have never read that GitHub Discussion, so listing those issues here is a service to them, just as listing the changes to the proposal since the Discussion is a service to those who had. (The rest of this comment was drafted two weeks ago.)
For the most part, I split my comments to facilitate voting on the suggestions/ideas, but it looks like there were a couple comments that mistakenly grouped stuff together they shouldn't have. The questions and corrections were batched together because they're not meant to be voted on. (I note that you still haven't answered the questions.) Some things were posted as they came up while I was drafting other comments. The comments weren't all written or submitted at once. Perhaps I should just put every separate thought in its own comment. That would be simpler, but I hate the thought of the noise.
I'm not sure what you're referring to. Can you be specific? If I could have knowingly run code to answer a question, I would have.
The proposal says that the prototype will be used, presumably as-is. For all I know, issues filed there now will never be addressed. This seems to be the appropriate place to report them now.
Can you identify which specific points you're referring to, and link to or quote how you addressed them, instead of painting all the points with the same brush? For all we know, you may be mistaken. The community needs to be able to judge for themselves. Unfortunately, your assurances that you've struck the right design and engineering trade-offs aren't convincing in and of themselves. |
Speaking as the editor of 8259, although most credit has to go to Doug Crockford who wrote the original RFC4627 many years ago… the spec says what it says, not what Doug or I thought we meant, but FWIW I think that “JSON text” refers to the bits on the wire or the bytes on the disk, which earn that name by conforming to the grammar productions in the RFC. Given that, "jsontext" seems like a perfectly appropriate name for the lowest-level API used for addressing those bytes & bytes. |
@willfaught the discussion is there for anyone interested to read. There is no need to replicate everything here, either wise there is no need for a discussion before a proposal in the first place. |
|
I haven’t followed the full conversation leading up to this proposal, so apologies if I’m bringing up something already discussed. I really like this proposal! But I wonder—could this be an opportunity to introduce a more generalized approach to marshaling/unmarshaling data in Go? Something like Rust’s Serde (not a big Rust fan myself, but having a standard serialization framework is pretty nice). For example, there could be a generic way to (un)marshal data, similar to what’s outlined here, taking an Encoder + options, but making the Encoder/Decoder more general-purpose, such that various encoding formats (JSON, CBOR, etc.) could implement their own. That way, different formats could share the same reflection machine, walking of the structs, etc. On top of that, maybe encoders could use a well-known registry interface, so custom encodings for types wouldn’t require modifying those types. That’d make it easier to define custom codecs (e.g., for time.Time) without conflicts across packages. A program could set up its own codec early on and use it consistently for marshaling/unmarshaling. |
|
@burdiyan this was briefly discussed in #63397 (comment), but it didn't really go anywhere - primarily as it's not clear if such an approach would work in Go, or what it would look like. It seems to me like it would need to be a separate proposal, as it would affect more than just JSON if accepted. And ideally we don't hold up json/v2 for another year or two while we figure out if such an approach is viable. |
|
@doggedOwl I'm going to reply because you bring up points I forgot to make in my last comment.
That isn't compatible with the Go proposal process. Preliminary, informal discussions elsewhere on GitHub, Reddit, Slack, Discord, Twitter, email, etc. don't count, and pose an undue burden on people trying to participate as commenters in the proposal process.
To my recollection, every point I raised here except for one (the name of jsontext) was new. I'd never brought them up before, and neither had others. That's why I asked @dsnet to cite where he addressed them previously: because I didn't know what he was talking about. What he said was (I assume unintentionally) misleading, and many readers won't go back and check the old GitHub discussion for themselves, which is why the first quotation above is a bad idea. |
This is a serious accusation. I have known Joe personally and professionally for many years. He is serious, impeccably honest, and dedicated. (And, I will note, is doing this work as a service to the community, not as his job.) Please rethink your tone. |
|
@josharian What I meant was that what he said was misleading. "To mislead" can be done with malicious intent or unintentionally. I suggest you remember that part of the Go code of conduct is to be charitable. I've never questioned his motives. I've thanked @dsnet more than once for his hard work on this project, and I would have thanked him once more in my planned last feedback comment here, but I never got there. I apologize if my phrasing implied malicious intent. |
|
This conversation has unfortunately gotten heated. I think everybody needs to step back and focus on any remaining technical details, not on discussions of what was said before and when, not on discussions for how to approach this proposal, not on requests for citations. Thanks. |
|
How far does this proposal address cleaning up invalid json tags in the standard library? |
Proposal Details
This is a formal proposal for the addition of "encoding/json/v2" and "encoding/json/jsontext" packages that has previously been discussed in #63397.
This focuses on just the newly added API. An argument justifying the need for a v2 package can be found in prior discussion. Alternatively, you can watch the GopherCon talk entitled "The Future of JSON in Go".
Most of the API proposal below is copied from the discussion. If you've already read the discussion and only want to know what changed relative to the discussion, skip over to the "Changes from discussion" section.
This is the largest major revision of a standard Go package to date, so there will be many reasonable threads of further discussion. Before commenting, please check the list of sub-issues to see if your comment is better suited in a particular sub-issue. We'll be using sub-issues to isolate and focus discussion on particular topics.
Thank you to everyone who has been involved with the discussion, design review, code review, etc. This proposal is better off because of all your feedback.
This proposal was written with feedback from @mvdan, @johanbrandhorst, @rogpeppe, @ChrisHines, @neild, and @rsc.
Overview
In general, we propose the addition of the following:
JSON serialization can be broken down into two primary components:
We use the terms "encode" and "decode" to describe syntactic functionality and the terms "marshal" and "unmarshal" to describe semantic functionality.
We aim to provide a clear distinction between functionality that is purely concerned with encoding versus that of marshaling. For example, it should be possible to encode a stream of JSON tokens without needing to marshal a concrete Go value representing them. Similarly, it should be possible to decode a stream of JSON tokens without needing to unmarshal them into a concrete Go value.
This diagram provides a high-level overview of the v2 API. Purple blocks represent types, while blue blocks represent functions or methods. The direction of the arrows represent the approximate flow of data. The bottom half (as implemented by the "jsontext" package) of the diagram contains functionality that is only concerned with syntax, while the upper half (as implemented by the "json" package) contains functionality that assigns semantic meaning to syntactic data handled by the bottom half.
Package "encoding/json/jsontext"
The
jsontextpackage provides functionality to process JSON purely according to the grammar.Overview
The basic API consists of the following:
Tokens and Values
The primary data types for interacting with JSON are
Kind,Token, andValue.The
Kindis an enumeration that describes the kind of a token or value.At present, there are no constants declared for individual kinds since each value is humanly readable. Declaring constants will lead to inconsistent usage where some users use the
'n'byte literal, while other users reference thejsontext.KindNullconstant. This is a similar problem to the introduction of thehttp.MethodGetconstant, which has led to inconsistency in codebases where the"GET"literal is more frequently used (~75% of the time).A
Tokenrepresents a lexical JSON token, which cannot represent entire array or object values. It is analogous to the v1Tokentype, but is designed to be allocation-free by being an opaque struct type.A
Valueis the raw representation of a single JSON value so, unlikeToken, can also represent entire array or object values. It is analogous to the v1RawMessagetype.By default,
IsValidvalidates according to RFC 7493, but accepts options to validate according to looser guarantees (such as allowing duplicate names or invalid UTF-8).The
Formatmethod formats the value according to the specified encoder options.The
CompactandIndentmethods operate similar to the v1CompactandIndentfunctions.The
Canonicalizemethod canonicalizes the JSON value according to the JSON Canonicalization Scheme as defined in RFC 8785.The
Compact,Indent, andCanonicalizeeach callFormatwith a default list of options. The caller may provide additional options to override the defaults.Formatting
Some top-level functions are provided for formatting JSON values and strings.
Encoder and Decoder
The
EncoderandDecodertypes provide the functionality for encoding to or decoding from anio.Writeror anio.Reader. AnEncoderorDecodercan be constructed withNewEncoderorNewDecoderusing default options.The
Encoderis a streaming encoder from raw JSON tokens and values. It is used to write a stream of top-level JSON values, each terminated with a newline character.The
Decoderis a streaming decoder for raw JSON tokens and values. It is used to read a stream of top-level JSON values, each separated by optional whitespace characters.Some methods common to both
EncoderandDecoderreport information about the current automaton state.Options
The behavior of
EncoderandDecodermay be altered by passing options toNewEncoderandNewDecoder, which take in a variadic list of options.The
Optionstype is a type alias to an internal type that is an interface type with no exported methods. It is used simply as a marker type for options declared in the "json" and "jsontext" packages.Latter options specified in the variadic list passed to
NewEncoderandNewDecodertake precedence over prior option values. For example,NewEncoder(AllowInvalidUTF8(false), AllowInvalidUTF8(true))results inAllowInvalidUTF8(true)taking precedence.Options that do not affect the operation in question are ignored. For example, passing
MultilinetoNewDecoderdoes nothing.The
WithIndentandWithIndentPrefixflags configure the appearance of whitespace in the output. Their semantics are identical to the v1Encoder.SetIndentmethod.Errors
Errors due to non-compliance with the JSON grammar are reported as a
SyntacticError.Errors due to I/O are returned as an opaque error that unwrap to the original error returned by the failing
io.Reader.Readorio.Writer.Writecall.ErrDuplicateNameandErrNonStringNameare sentinel errors that arereturned while being wrapped within a
SyntacticError.Pointeris a named type representing a JSON Pointer (RFC 6901) and references a particular JSON value relative to a top-level JSON value. It is primarily used for error reporting, but its utility could be expanded in the future (e.g. extracting or modifying a portion of aValuebyPointerreference alone).Package "encoding/json/v2"
The v2 "json" package provides functionality to marshal or unmarshal JSON data from or into Go value types. This package depends on "jsontext" to process JSON text and the "reflect" package to dynamically introspect Go values at runtime.
Most users will interact directly with the "json" package without ever needing to interact with the lower-level "jsontext package.
Overview
The basic API consists of the following:
The
MarshalandUnmarshalfunctions mostly match the signature of the same functions in v1, however their behavior differs.The
MarshalWriteandUnmarshalReadfunctions are equivalent functionality that operate on anio.Writerandio.Readerinstead of[]byte. TheUnmarshalReadfunction consumes the entire input untilio.EOFand reports an error if any invalid tokens appear after the end of the JSON value (#36225).The
MarshalEncodeandUnmarshalDecodefunctions are equivalent functionality that operate on an*jsontext.Encoderand*jsontext.Decoderinstead of[]byte. UnlikeUnmarshalRead,UnmarshalDecodedoes not read untilio.EOF, allowing successive calls to process each JSON value as a stream.All marshal and unmarshal functions accept a variadic list of options
that configure the behavior of serialization.
Default behavior
The marshal and unmarshal logic in v2 is mostly identical to v1 with following changes:
In v1, JSON object members are unmarshaled into a Go struct using a case-insensitive name match with the JSON name of the fields. In contrast, v2 matches fields using an exact, case-sensitive match. The
MatchCaseInsensitiveNamesandjsonv1.MatchCaseSensitiveDelimiteroptions control this behavior difference. To explicitly specify a Go struct field to use a particular name matching scheme, either thenocaseor thestrictcasefield option can be specified. Field-specified options take precedence over caller-specified options.In v1, when marshaling a Go struct, a field marked as
omitemptyis omitted if the field value is an "empty" Go value, which is defined as false, 0, a nil pointer, a nil interface value, and any empty array, slice, map, or string. In contrast, v2 redefinesomitemptyto omit a field if it encodes as an "empty" JSON value, which is defined as a JSON null, or an empty JSON string, object, or array. Thejsonv1.OmitEmptyWithLegacyDefinitionoption controls this behavior difference. Note thatomitemptybehaves identically in both v1 and v2 for a Go array, slice, map, or string (assuming no user-definedMarshalJSONmethod overrides the default representation). Existing usages ofomitemptyon a Go bool, number, pointer, or interface value should migrate to specifyingomitzeroinstead (which is identically supported in both v1 and v2). See prior discussion for more information.In v1, a Go struct field marked as
stringcan be used to quote a Go string, bool, or number as a JSON string. It does not recursively take effect on composite Go types. In contrast, v2 restricts thestringoption to only quote a Go number as a JSON string. It does recursively take effect on Go numbers within a composite Go type. Thejsonv1.StringifyWithLegacySemanticsoption controls this behavior difference.In v1, a nil Go slice or Go map is marshaled as a JSON null. In contrast, v2 marshals a nil Go slice or Go map as an empty JSON array or JSON object, respectively. The
FormatNilSliceAsNullandFormatNilMapAsNulloptions control this behavior difference. To explicitly specify a Go struct field to use a particular representation for nil, either theformat:emitemptyorformat:emitnullfield option can be specified. Field-specified options take precedence over caller-specified options. See prior discussion for more information.In v1, a Go array may be unmarshaled from a JSON array of any length. In contrast, in v2 a Go array must be unmarshaled from a JSON array of the same length, otherwise it results in an error. The
jsonv1.UnmarshalArrayFromAnyLengthoption controls this behavior difference.In v1, a Go byte array (i.e.,
~[N]byte) is represented as a JSON array of JSON numbers. In contrast, in v2 a Go byte array is represented as a Base64-encoded JSON string. Thejsonv1.FormatBytesWithLegacySemanticsoption controls this behavior difference. To explicitly specify a Go struct field to use a particular representation, either theformat:arrayorformat:base64field option can be specified. Field-specified options take precedence over caller-specified options.In v1,
MarshalJSONmethods declared on a pointer receiver are only called if the Go value is addressable. In contrast, in v2 aMarshalJSONmethod is always callable regardless of addressability. Thejsonv1.CallMethodsWithLegacySemanticsoption controls this behavior difference.In v1,
MarshalJSONandUnmarshalJSONmethods are never called for Go map keys. In contrast, in v2 aMarshalJSONorUnmarshalJSONmethod is eligible for being called for Go map keys. Thejsonv1.CallMethodsWithLegacySemanticsoption controls this behavior difference.In v1, a Go map is marshaled in a deterministic order. In contrast, in v2 a Go map is marshaled in a non-deterministic order. The
Deterministicoption controls this behavior difference. See prior discussion for more information.In v1, JSON strings are encoded with HTML-specific or JavaScript-specific characters being escaped. In contrast, in v2 JSON strings use the minimal encoding and only escape if required by the JSON grammar. The
jsontext.EscapeForHTMLandjsontext.EscapeForJSoptions control this behavior difference.In v1, bytes of invalid UTF-8 within a string are silently replaced with the Unicode replacement character. In contrast, in v2 the presence of invalid UTF-8 results in an error. The
jsontext.AllowInvalidUTF8option controls this behavior difference.In v1, a JSON object with duplicate names is permitted. In contrast, in v2 a JSON object with duplicate names results in an error. The
jsontext.AllowDuplicateNamesoption controls this behavior difference.In v1, when unmarshaling a JSON null into a non-empty Go value it will inconsistently either zero out the value or do nothing. In contrast, in v2 unmarshaling a JSON null will consistently and always zero out the underlying Go value. The
jsonv1.MergeWithLegacySemanticsoption controls this behavior difference.In v1, when unmarshaling a JSON value into a non-zero Go value, it merges into the original Go value for array elements, slice elements, struct fields (but not map values), pointer values, and interface values (only if a non-nil pointer). In contrast, in v2 unmarshal merges into the Go value for struct fields, map values, pointer values, and interface values. In general, the v2 semantic merges when unmarshaling a JSON object, otherwise it replaces the value. The
jsonv1.MergeWithLegacySemanticsoption controls this behavior difference.In v1, a
time.Durationis represented as a JSON number containing the decimal number of nanoseconds. In contrast, in v2 atime.Durationis represented as a JSON string containing the formatted duration (e.g., "1h2m3.456s") according totime.Duration.String. Thejsonv1.FormatTimeWithLegacySemanticsoption controls this behavior difference. To explicitly specify a Go struct field to use a particular representation, either theformat:nanoorformat:unitsfield option can be specified. Field-specified options take precedence over caller-specified options.In v1, errors are never reported at runtime for Go struct types that have some form of structural error (e.g., a malformed tag option). In contrast, v2 reports a runtime error for Go types that are invalid as they relate to JSON serialization. For example, a Go struct with only unexported fields cannot be serialized. The
jsonv1.ReportErrorsWithLegacySemanticsoption controls this behavior difference.While the behavior of
MarshalandUnmarshalin "json/v2" is changing relative to v1 "json", note that the behavior of v1 "json" remains as is.Struct tag options
Similar to v1, v2 also supports customized representation of Go struct fields through the use of struct tags. As before, the
jsontag will be used. The following tag options are supported:omitzero: When marshaling, the "omitzero" option specifies that the struct field should be omitted if the field value is zero, as determined by the "IsZero() bool" method, if present, otherwise based on whether the field is the zero Go value (per
reflect.Value.IsZero). This option has no effect when unmarshaling. (example)omitempty: When marshaling, the "omitempty" option specifies that the struct field should be omitted if the field value would have been encoded as a JSON null, empty string, empty object, or empty array. This option has no effect when unmarshaling. (example)
string: The "string" option specifies that
StringifyNumbersbe set when marshaling or unmarshaling a struct field value. This causes numeric types to be encoded as a JSON number within a JSON string, and to be decoded from a JSON string containing a JSON number. This extra level of encoding is often necessary since many JSON parsers cannot precisely represent 64-bit integers.nocase: When unmarshaling, the "nocase" option specifies that if the JSON object name does not exactly match the JSON name for any of the struct fields, then it attempts to match the struct field using a case-insensitive match that also ignores dashes and underscores. (example)
strictcase: When unmarshaling, the "strictcase" option specifies that the JSON object name must exactly match the JSON name for the struct field. This takes precedence even if MatchCaseInsensitiveNames is set to true. This cannot be specified together with the "nocase" option.
MatchCaseInsensitiveNamesfrom taking effect on a particular field. This option provides a means to opt-into the v2-like behavior.inline: The "inline" option specifies that the JSON object representation of this field is to be promoted as if it were specified in the parent struct. It is the JSON equivalent of Go struct embedding. A Go embedded field is implicitly inlined unless an explicit JSON name is specified. The inlined field must be a Go struct that does not implement
MarshalerorUnmarshaler. Inlined fields of typejsontext.Valueandmap[~string]Tare called “inlined fallbacks”, as they can represent all possible JSON object members not directly handled by the parent struct. Only one inlined fallback field may be specified in a struct, while many non-fallback fields may be specified. This option must not be specified with any other tag option. (example)jsontext.Value(#6213).unknown: The "unknown" option is a specialized variant of the inlined fallback to indicate that this Go struct field contains any number of “unknown” JSON object members. The field type must be a
jsontext.Valueor amap[~string]T. IfDiscardUnknownMembersis specified when marshaling, the contents of this field are ignored. IfRejectUnknownMembersis specified when unmarshaling, any unknown object members are rejected even if a field exists with the "unknown" option. This option must not be specified with any other tag option. (example)format: The "format" option specifies a format flag used to specialize the formatting of the field value. The option is a key-value pair specified as "format:value" where the value must be either a literal consisting of letters and numbers (e.g., "format:RFC3339") or a single-quoted string literal (e.g., "format:'2006-01-02'"). The interpretation of the format flag is determined by the struct field type. (example)
New in v2. The "format" option provides a general way to customize formatting of arbitrary types.
[]byteand[N]bytetypes accept "format" values of either "base64", "base64url", "base32", "base32hex", "base16", or "hex", where it represents the binary bytes as a JSON string encoded using the specified format in RFC 4648. It may also be "array" to treat the slice or array as a JSON array of numbers. The "array" format exists for backwards compatibility since the default representation of an array of bytes now uses Base-64.float32andfloat64types accept a "format" value of "nonfinite", where NaN and infinity are represented as JSON strings.Slice types accept a "format" value of "emitnull" to marshal a nil slice as a JSON null instead of an empty JSON array. (more discussion).
Map types accept a "format" value of "emitnull" to marshal a nil map as a JSON null instead of an empty JSON object. (more discussion).
The
time.Timetype accepts a "format" value which may either be a Go identifier for one of the format constants (e.g., "RFC3339") or the format string itself to use withtime.Time.Formatortime.Parse(#21990). It can also be "unix", "unixmilli", "unixmicro", or "unixnano" to be represented as a decimal number reporting the number of seconds (or milliseconds, etc.) since the Unix epoch.The
time.Durationtype accepts a "format" value of "sec", "milli", "micro", or "nano" to represent it as the number of seconds (or milliseconds, etc.) formatted as a JSON number. This exists for backwards compatibility since the default representation now uses a string representation (e.g., "53.241s"). If the format is "base60", it is encoded as a JSON string using the "H:MM:SS.SSSSSSSSS" representation.The "omitzero" and "omitempty" options are similar. The former is defined in terms of the Go type system, while the latter in terms of the JSON type system. Consequently they behave differently in some circumstances. For example, only a nil slice or map is omitted under "omitzero", while an empty slice or map is omitted under "omitempty" regardless of nilness. The "omitzero" option is useful for types with a well-defined zero value (e.g.,
netip.Addr) or have anIsZeromethod (e.g.,time.Time).Note that all tag options labeled with "Changed in v2" will behave as it has always historically behaved when using v1 "json". However, all tag options labeled with "New in v2" will be implicitly and retroactively supported in v1 "json" because v1 will be implemented under-the-hood using "json/v2".
Type-specified customization
Go types may customize their own JSON representation by implementing certain interfaces that the "json" package knows to look for:
The v1
MarshalerandUnmarshalerinterfaces are supported in v2 to provide greater degrees of backward compatibility.The
MarshalerToandUnmarshalerFrominterfaces operate in a purely streaming manner and provide a means for plumbing down options. This API can provide dramatic performance improvements (see "Performance").If a type implements both sets of marshaling or unmarshaling interfaces, then the streaming variant takes precedence.
Just like v1,
encoding.TextMarshalerandencoding.TextUnmarshalerinterfaces remain supported in v2, where these interfaces are treated with lower precedence than JSON-specific serialization interfaces.Caller-specified customization
In addition to Go types being able to specify their own JSON representation, the caller of the marshal or unmarshal functionality can also specify their own JSON representation for specific Go types (#5901). Caller-specified customization takes precedence over type-specified customization.
Caller-specified customization is a powerful feature. For example:
RawNumbertype.Options
Options may be specified that configure how marshal and unmarshal operates:
The
Optionstype is a type alias to an internal type that is an interface type with no exported methods. It is used simply as a marker type for options declared in the "json" and "jsontext" package. This is exactly the sameOptionstype as the one in the "jsontext" package.The same
Optionstype is used for bothMarshalandUnmarshalas some options affect both operations.The
MarshalJSONTo,UnmarshalJSONFrom,MarshalToFunc, andUnmarshalFromFuncmethods and functions take in a singularOptionsvalue instead of a variadic list because theOptionstype can represent a set of options. The caller (which is the "json" package) can coalesce a list of options before calling the user-specified method or function. Being given a singleOptionsvalue is more ergonomic for the user as there is only one options value to introspect withGetOption.Errors
Errors due to the inability to correlate JSON data with Go data are reported as
SemanticError.ErrUnknownNameis a sentinel error that is returned while being wrapped within aSemanticError.Package "encoding/json"
The API and behavior for v1 "json" remains unchanged except for the addition of new options to configure v2 to operate with legacy v1 behavior.
Options
Options may be specified that configures v2 "json" to operate with legacy v1 behavior:
Many of the options configure fairly obscure behavior. Unfortunately, many of the behaviors cannot be changed in order to maintain backwards compatibility. This is a major justification for a v2 "json" package.
Let
jsonv1be v1 "encoding/json" andjsonv2be "encoding/json/v2", then the v1 and v2 options can be composed together to obtain behavior that is identical to v1, identical to v2, or anywhere in between. For example:jsonv1.Marshal(v)jsonv2.Marshal(in, jsonv1.DefaultOptionsV1())jsonv1.Marshaljsonv2.Marshal(in, jsonv1.DefaultOptionsV1(), jsontext.AllowDuplicateNames(false))jsonv2.Marshal(in, jsonv1.StringifyWithLegacySemantics(true), jsonv1.ReportErrorsWithLegacySemantics(true))jsonv2.Marshal(v, ..., jsonv2.DefaultOptionsV2())jsonv2.Marshalsincejsonv2.DefaultOptionsV2overrides any options specified earlier in the...jsonv2.Marshal(v)Types aliases
The following types are moved to v2 "json":
Number methods
The
Numbertype no longer has special-case support in the "json" implementation itself.So methods are added to have it implement the v2
MarshalerToandUnmarshalerFrommethods to preserve equivalent behavior.Errors
The
UnmarshalTypeErrortype is extended to wrap an underlying error:Errors returned by v2 "json" are much richer, so the wrapped error provides a way for v1 "json" to preserve some of that context, while still using the
UnmarshalTypeErrortype, which many programs may still be expecting.The
UnmarshalTypeError.Fieldnow reports a dot-delimited path to the error value where each path segment is either a JSON array and map index operation. This is a divergence from prior behavior which was always inconsistent about whether the position was reported according to the Go namespace or the JSON namespace (see #43126).The text was updated successfully, but these errors were encountered: