unable to use azure disk in StatefulSet since /dev/sd* changed after detach/attach disk #1918
Comments
|
according to your provided logs, If azure disk state really changed from readwrite to readonly in your pod, could you log on the agent node, and check in VM? Thanks. |
|
@andyzhangx Thanks for your help,we use standard examples,and the it works well.But I don't kown why only our disks are unreadable.
and we find after we delete the pod,and it recreate. |
|
@sblyk could you print out |
|
@sblyk also, you could check whether disks are attached to agent VM in azure portal if you found one disk is readonly, the disk name is in the format like |
|
@andyzhangx yes, different StatefulSet use different PV.these statefulsets are in different namespaces. |
|
@sblyk when you found disk |
|
@andyzhangx |
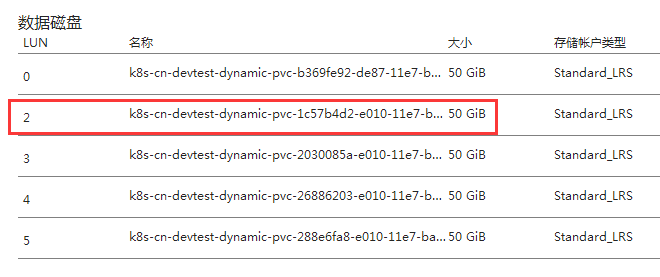
|
@sblyk thanks for the info. We are close to get the root cause. Pls keep this env for debugging, thanks! |
|
@andyzhangx we can only use sdg ,the error message when we use other directories: |

|
@sblyk could you also run "fdisk -l" on your agent VM? Thanks. |
|
|
could you format the disk |
and then try to use |
|
also, could you collect the kubelet logs on agent VM? Thanks. |
|
@andyzhangx the disk sdk was mounted successfully kubelet logs on agent VM: |
|
@sblyk one finding: The usable disk(sdg) is from storage account: appdatacnuat |
|
one possibility is that storage account pvc300170136002 contains too many azure disks, there would be IOPS throttling. Could you check how many azure disks totally are in your pvc300170136002? And the reason why you would use pvc300170136002 is that you did not specify storage account in your azure disk storage class. |
|
@andyzhangx at first we create some statefulsets like this: to |
|
@sblyk In your |
|
@andyzhangx yes I'm sure it's the same VM |
|
@sblyk Could you run following command to rescan host scsi (you need to run as root) And then check following device: |
|
@andyzhangx this is the output |
|
@sblyk one workaround is reboot your agent which has this issue, just don't know why would your disk |
|
@andyzhangx not only this agent,we have 6 agents,all have this issue. |
|
@khenidak Did you got such case in the before that /dev/sd* changed to other dev name and k8s just did not detect it? In this case, |
|
@sblyk could you reboot agent to check whether that issue exists any more? Another question, I found LUN 1 is not used in this agent VM? is it the same for other VM? Thanks. |
|
@andyzhangx
|

|
@sblyk thanks for the check. Could you share the complete statefulset config? I would like to do a deep investigation tomorrow. And pls note that azure disk could only be attached to one VM, there could be problem when migrate one pod from one vm to another vm, since disk detach and attachment would take a few minutes. I would suggest you use azure file instead, it could be mounted in multiple VMs. You could find azure file example here: BTW, |
|
@sblyk I have identified this is a bug for azure disk since it's using |
|
@sblyk again, thanks for the reporting, I am now working on a fix in k8s upstream. |
Automatic merge from submit-queue (batch tested with PRs 56382, 57549). If you want to cherry-pick this change to another branch, please follow the instructions <a href="https://github.com/kubernetes/community/blob/master/contributors/devel/cherry-picks.md">here</a>. fix azure disk not available issue when device name changed **What this PR does / why we need it**: There is possibility that device name(`/dev/sd*`) would change when attach/detach data disk in Azure VM according to [Troubleshoot Linux VM device name change](https://docs.microsoft.com/en-us/azure/virtual-machines/linux/troubleshoot-device-names-problems). And We did hit this issue, see customer [case](Azure/acs-engine#1918). This PR would use `/dev/disk/by-id` instead of `/dev/sd*` for azure disk and `/dev/disk/by-id` would not change even device name changed. **Which issue(s) this PR fixes** *(optional, in `fixes #<issue number>(, fixes #<issue_number>, ...)` format, will close the issue(s) when PR gets merged)*: Fixes #57444 **Special notes for your reviewer**: In a customer [case](Azure/acs-engine#1918), customer is unable to use azure disk in StatefulSet since /dev/sd* changed after detach/attach disk. we are using `/dev/sd*`(code is [here](https://github.com/kubernetes/kubernetes/blob/master/pkg/volume/azure_dd/azure_common_linux.go#L140)) to "mount -bind" k8s path, while `/dev/sd*` could be changed when VM is attach/detaching data disks, see [Troubleshoot Linux VM device name change](https://docs.microsoft.com/en-us/azure/virtual-machines/linux/troubleshoot-device-names-problems) And I have also checked related AWS, GCE code, they are using `/dev/disk/by-id/` other than `/dev/sd*`, see [aws code](https://github.com/kubernetes/kubernetes/blob/master/pkg/volume/aws_ebs/aws_util.go#L228) [gce code](https://github.com/kubernetes/kubernetes/blob/master/pkg/volume/gce_pd/gce_util.go#L278) **Release note**: ``` fix azure disk not available when device name changed ``` /sig azure /assign @rootfs @karataliu @brendandburns @khenidak
|
@sblyk finally I fixed this issue, I wrote a doc describe details about this issue: Fix or workaround:
|
Automatic merge from submit-queue (batch tested with PRs 60346, 60135, 60289, 59643, 52640). If you want to cherry-pick this change to another branch, please follow the instructions <a href="https://github.com/kubernetes/community/blob/master/contributors/devel/cherry-picks.md">here</a>. fix device name change issue for azure disk **What this PR does / why we need it**: fix device name change issue for azure disk due to default host cache setting changed from None to ReadWrite from v1.7, and default host cache setting in azure portal is `None` **Which issue(s) this PR fixes** *(optional, in `fixes #<issue number>(, fixes #<issue_number>, ...)` format, will close the issue(s) when PR gets merged)*: Fixes #60344, #57444 also fixes following issues: Azure/acs-engine#1918 Azure/AKS#201 **Special notes for your reviewer**: From v1.7, default host cache setting changed from None to ReadWrite, this would lead to device name change after attach multiple disks on azure vm, finally lead to disk unaccessiable from pod. For an example: statefulset with 8 replicas(each with an azure disk) on one node will always fail, according to my observation, add the 6th data disk will always make dev name change, some pod could not access data disk after that. I have verified this fix on v1.8.4 Without this PR on one node(dev name changes): ``` azureuser@k8s-agentpool2-40588258-0:~$ tree /dev/disk/azure ... └── scsi1 ├── lun0 -> ../../../sdk ├── lun1 -> ../../../sdj ├── lun2 -> ../../../sde ├── lun3 -> ../../../sdf ├── lun4 -> ../../../sdg ├── lun5 -> ../../../sdh └── lun6 -> ../../../sdi ``` With this PR on one node(no dev name change): ``` azureuser@k8s-agentpool2-40588258-1:~$ tree /dev/disk/azure ... └── scsi1 ├── lun0 -> ../../../sdc ├── lun1 -> ../../../sdd ├── lun2 -> ../../../sde ├── lun3 -> ../../../sdf ├── lun5 -> ../../../sdh └── lun6 -> ../../../sdi ``` Following `myvm-0`, `myvm-1` is crashing due to dev name change, after controller manager replacement, myvm2-x pods work well. ``` Every 2.0s: kubectl get po Sat Feb 24 04:16:26 2018 NAME READY STATUS RESTARTS AGE myvm-0 0/1 CrashLoopBackOff 13 41m myvm-1 0/1 CrashLoopBackOff 11 38m myvm-2 1/1 Running 0 35m myvm-3 1/1 Running 0 33m myvm-4 1/1 Running 0 31m myvm-5 1/1 Running 0 29m myvm-6 1/1 Running 0 26m myvm2-0 1/1 Running 0 17m myvm2-1 1/1 Running 0 14m myvm2-2 1/1 Running 0 12m myvm2-3 1/1 Running 0 10m myvm2-4 1/1 Running 0 8m myvm2-5 1/1 Running 0 5m myvm2-6 1/1 Running 0 3m ``` **Release note**: ``` fix device name change issue for azure disk ``` /assign @karataliu /sig azure @feiskyer could you mark it as v1.10 milestone? @brendandburns @khenidak @rootfs @jdumars FYI Since it's a critical bug, I will cherry pick this fix to v1.7-v1.9, note that v1.6 does not have this issue since default cachingmode is `None`
|
@andyzhangx Thank you!I tested it yesterday. |
|
@sblyk would you close this issue then? |
Is this change save for the disk? I mean what happened to the data after changing the cachingmode? |
|
@foosome what's your issue here? |
I 'm using Alibaba Cloud Solved with creating StorageClass with adding cachingmode parameter Thank You @andyzhangx ! |
|
@foosome but |
Yes, with default storageclass I got the same issue.
|
|
@foosome no |
Is this a request for help?:
yes
Is this an ISSUE or FEATURE REQUEST? (choose one):
ISSUE
What version of acs-engine?:
v0.9.1
Orchestrator and version (e.g. Kubernetes, DC/OS, Swarm)
Kubernetes v1.7.9
What happened:
We create a storageClass
then we create statefulset to use it
At first, we could use this disk normally, but after a period of time, we found that the state of the disk changed to read-only. After the deletion of pod, the newly generated pod could use the same disk, but after a period of time, the disk became read-only again.
there are some error message in pod,u01 is our pv disk.
What you expected to happen:
Can normal use of dynamic disk
How to reproduce it (as minimally and precisely as possible):
Anything else we need to know:
The text was updated successfully, but these errors were encountered: